
В этой статье я расскажу как легко, быстро и бесплатно установить AI локально на локальный для вас компьютер. А в следующих статьях — мы будем подключать LLM к Obsidian для локальной работы AI, с нашей базой данных и обучать LLM.
Уровень статьи: простой
Оглавление
Термины и ссылки которые использованы в статье:
- AI — artificial Intelligence, искусственный интеллект.
- LLM — large language model, большая языковая модель.
- Dataset — данные для обучения AI.
- GUI — graphical user interface, графический пользовательский интерфейс.
- CLI — командная строка
- Ollama — приложение для установки и управление локальных LLM через терминал.
- LM Studio — приложение для установки и управление локальных LLM через GUI.
- Huggin Face — платформа ориентированное на создание и обмен моделями AI и Dataset. Как Github или Google Play, только для AI и Open Source.
Ollama
Ollama это приложение, которое поможет установить LLM локально на ваш компьютер, работает под Windows, Linux, MAC.
Ollama автоматически обнаруживает и использует доступные NVIDIA GPU. Убедитесь, что у вас установлены правильные (это касается Linux) драйверы NVIDIA. Для AMD GPU на Linux требуется ROCm.
Репозиторий Ollama:
- GitHub: Репозиторий Ollama на GitHub (https://github.com/ollama/ollama) — основное место для сообщения о проблемах (issues), обсуждения функций и получения помощи.
- Документация: Официальная документация Ollama (https://github.com/ollama/ollama/tree/main/docs) содержит много полезной информации.
- Сайт: Откуда проще всего скачать Ollama (https://ollama.com)
Установка Ollama
Установка супер-простая, скачиваем и устанавливаем приложение.
Запуск Ollama
Запуск и скачивание моделей для Ollama происходит через терминал, если для вас это уже сложно, посмотрите статью про LM Studio, там проще 🙂
Открываем терминал на любой из операционных систем (для Windows это может быть Power Shell, Командная строка или Терминал).
Выбираем модель на сайте Ollama в разделе Models
Ой, скрин не тот
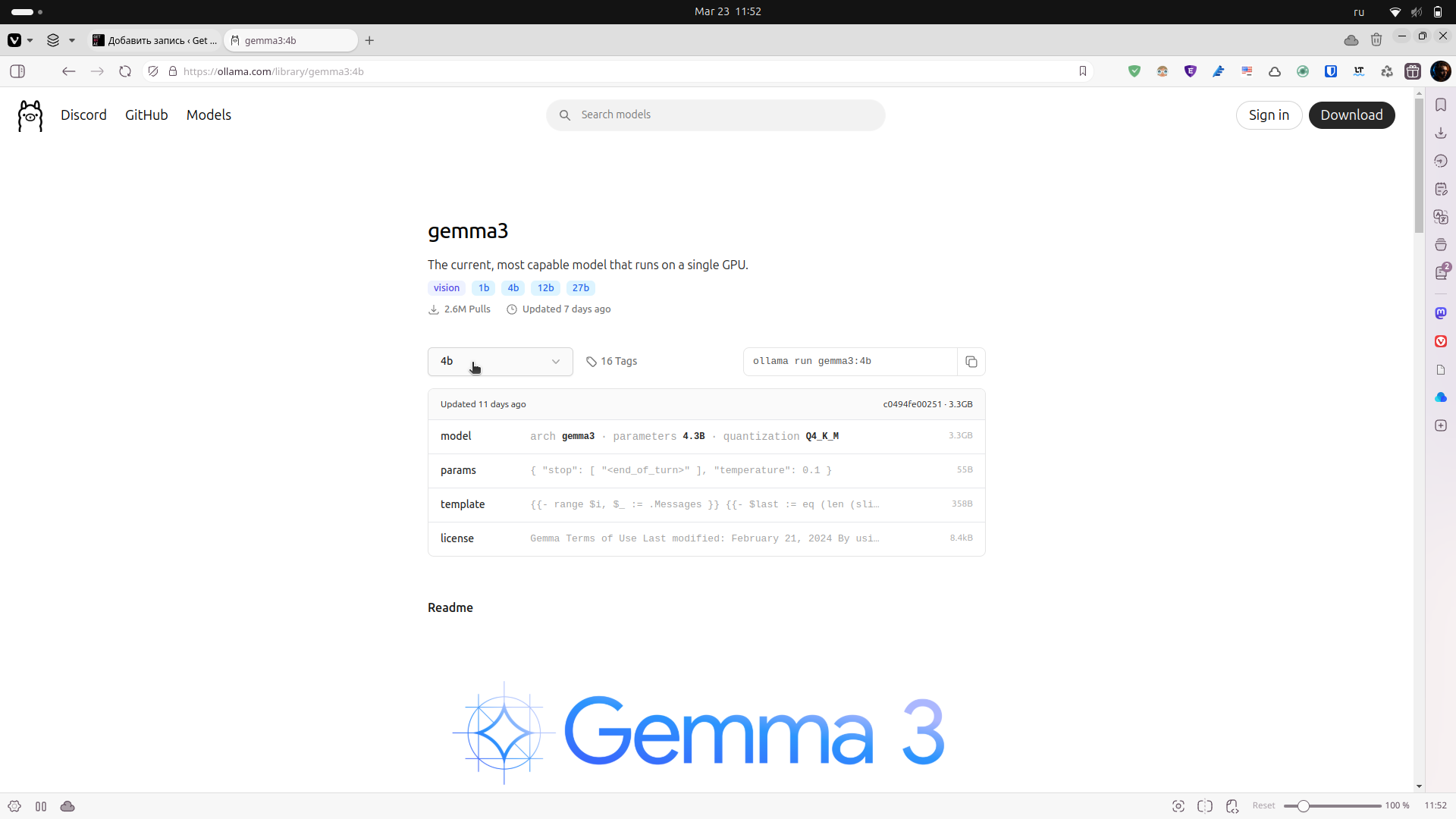
Здесь я выбрал Gemma3 с 4 миллиардами параметрами — gemma3:4b
Чтобы скачать и запустить:
ollama run gemma3:4bИ все, мы уже можем общаться с AI через консоль
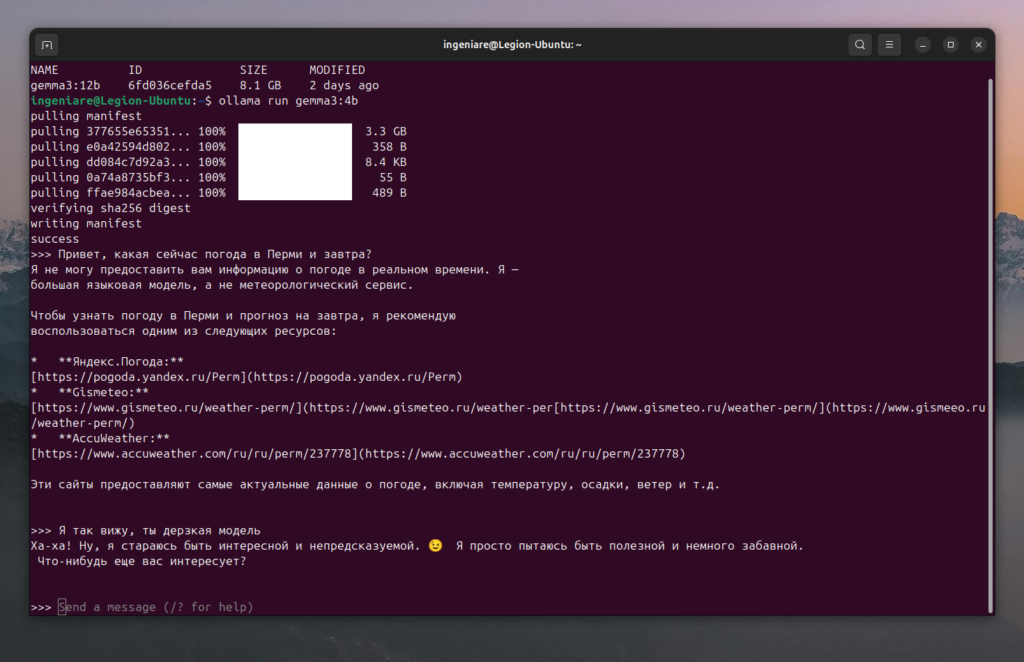
У меня достаточно дерзкая модель попалась, с характером 🙂
Здесь заканчивается базовая часть статьи!
Установка только с CPU, через Docker
Если у нас нет хорошей видеокарты GPU, мы можем использовать LLM с процессором CPU, для этого правда, нам уже нужно развернуть модель в Docker.
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollamaЕсли нужна установка через Docker Nvidia или AMD GPU, почитайте документацию — https://github.com/ollama/ollama/blob/main/docs/docker.md
Обновление Ollama
Ollama на macOS и Windows автоматически загружает обновления. Нажмите на значок на панели задач или в меню, а затем нажмите «Перезапустить для обновления», чтобы применить обновление. Обновления также можно установить, загрузив последнюю версию вручную.
В Linux повторно запустите установочный скрипт:
curl -fsSL https://ollama.com/install.sh | shКакая видеокарта рекомендуются?
Ollama хорошо работает с CUDA, это верно для всех AI систем из-за особенностей многоядерности CUDA.
Левая колонка — тем больше цифра, тем выше вычислительные возможности для AI.
| Вычислительные возможности | Семейство | Модели GPU |
|---|---|---|
| 9.0 | NVIDIA | H200 H100 |
| 8.9 | GeForce RTX 40xx | RTX 4090 RTX 4080 SUPER RTX 4080 RTX 4070 Ti SUPER RTX 4070 Ti RTX 4070 SUPER RTX 4070 RTX 4060 Ti RTX 4060 |
| Профессиональная компания NVIDIA | L4 L40 RTX 6000 | |
| 8.6 | GeForce RTX 30xx | RTX 3090 Ti RTX 3090 RTX 3080 Ti RTX 3080 RTX 3070 Ti RTX 3070 RTX 3060 Ti RTX 3060 RTX 3050 Ti RTX 3050 |
| Профессиональная компания NVIDIA | A40 RTX A6000 RTX A5000 RTX A4000 RTX A3000 RTX A2000 A10 A16 A2 | |
| 8.0 | NVIDIA | A100 A30 |
| 7.5 | GeForce GTX/RTX | GTX 1650 Ti TITAN RTX RTX 2080 Ti RTX 2080 RTX 2070 RTX 2060 |
| Профессиональная компания NVIDIA | T4 RTX 5000 RTX 4000 RTX 3000 T2000 T1200 T1000 T600 T500 | |
| Quadro | RTX 8000 RTX 6000 RTX 5000 RTX 4000 | |
| 7.0 | NVIDIA | TITAN V V100 Quadro GV100 |
| 6.1 | NVIDIA TITAN | TITAN Xp TITAN X |
| GeForce GTX | GTX 1080 Ti GTX 1080 GTX 1070 Ti GTX 1070 GTX 1060 GTX 1050 Ti GTX 1050 | |
| Quadro | P6000 P5200 P4200 P3200 P5000 P4000 P3000 P2200 P2000 P1000 P620 P600 P500 P520 | |
| Тесла | P40 P4 | |
| 6.0 | NVIDIA | Tesla P100 Quadro GP100 |
| 5.2 | GeForce GTX | GTX TITAN X GTX 980 Ti GTX 980 GTX 970 GTX 960 GTX 950 |
| Quadro | M6000 24GB M6000 M5000 M5500M M4000 M2200 M2000 M620 | |
| Тесла | M60 M40 | |
| 5.0 | GeForce GTX | GTX 750 Ti GTX 750 NVS 810 |
| Quadro | K2200 K1200 K620 M1200 M520 M5000M M4000M M3000M M2000M M1000M K620M M600M M500M |
Например, на моем ноутбукe с Nvidia 1650GT и 16 GB RAM достаточно хорошо (но не быстро) работают Gemma 12B. Для обучения LLM у меня ноут уже не потянет этот процесс.
Управление Ollama через CLI
Управление через командную строку или терминал (CLI) — основной способ взаимодействия. Вы вводите запросы после приглашения >>>, а модель генерирует ответы. Примеры команд:
ollama run gemma3:4b #Запустить модель.ollama list #Показать список доступных локально моделей.ollama pull gemma3:4b #Скачать модель, не запуская её.ollama rm gemma3:4b #Удалить модель.ollama cp <source_model> <target_model> #Скопировать модель.ollama show --modelfile gemma3:4b #Показать Modelfile для модели (подробнее о Modelfile будет отдельной статьей).ollama show --template gemma3:4b #Показать шаблон запроса для модели.Итак, в этой статье мы научились устанавливать и управлять Ollama на нашем компьютере, в следующих статьях про Ollama, мы будем дальше развиваться наше взаимодействие с ним.


